
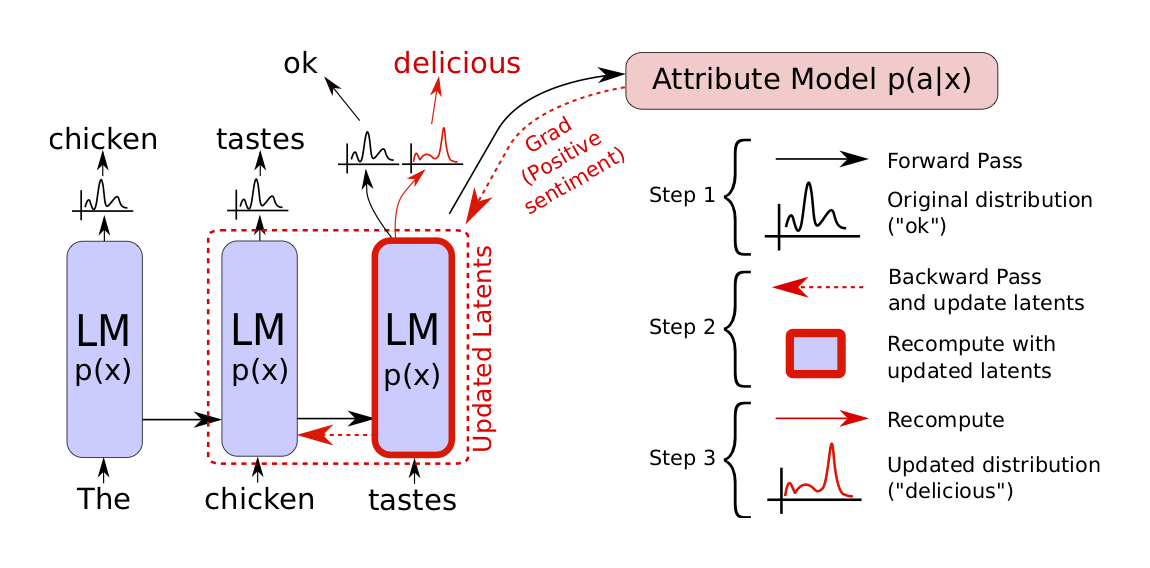
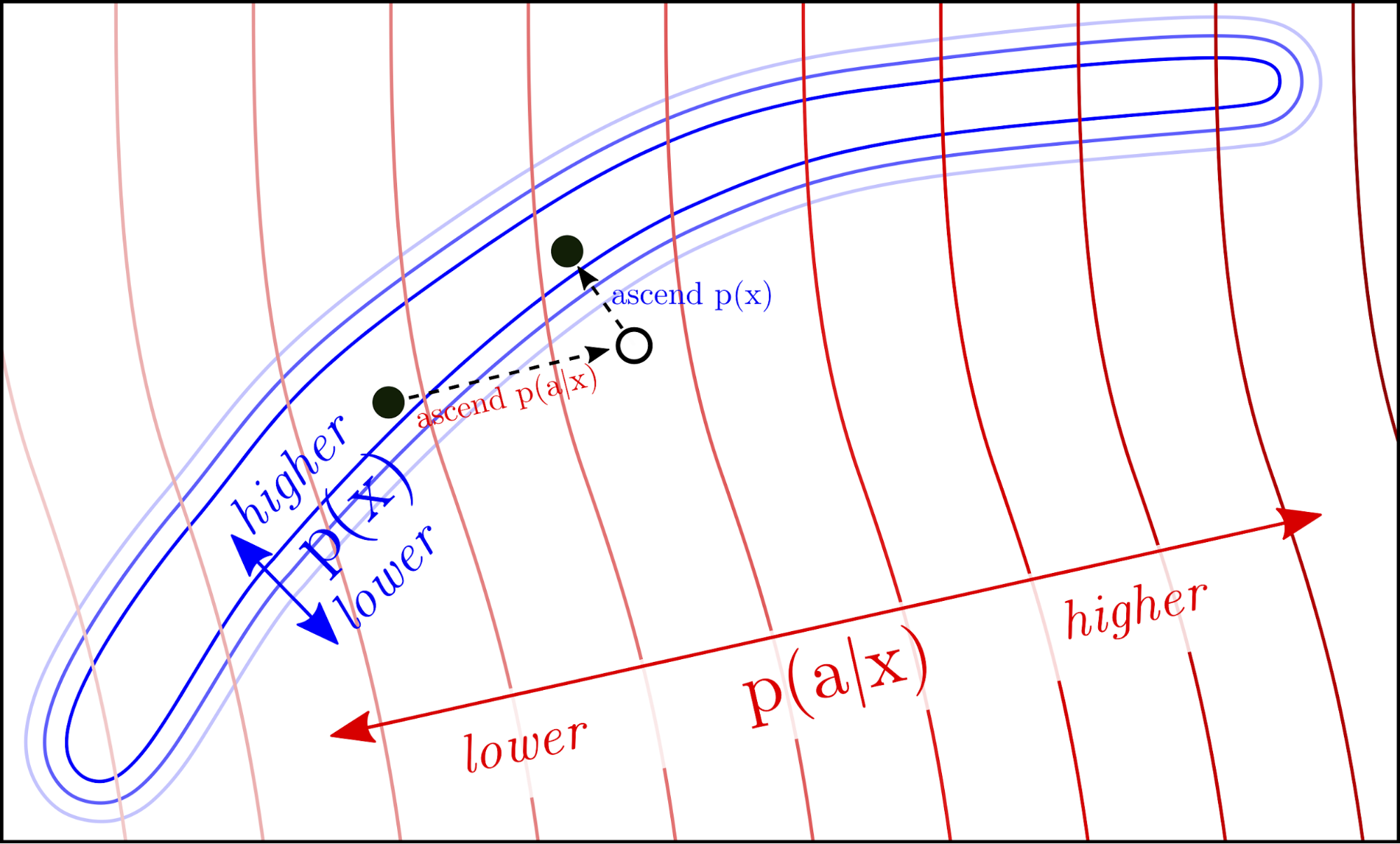





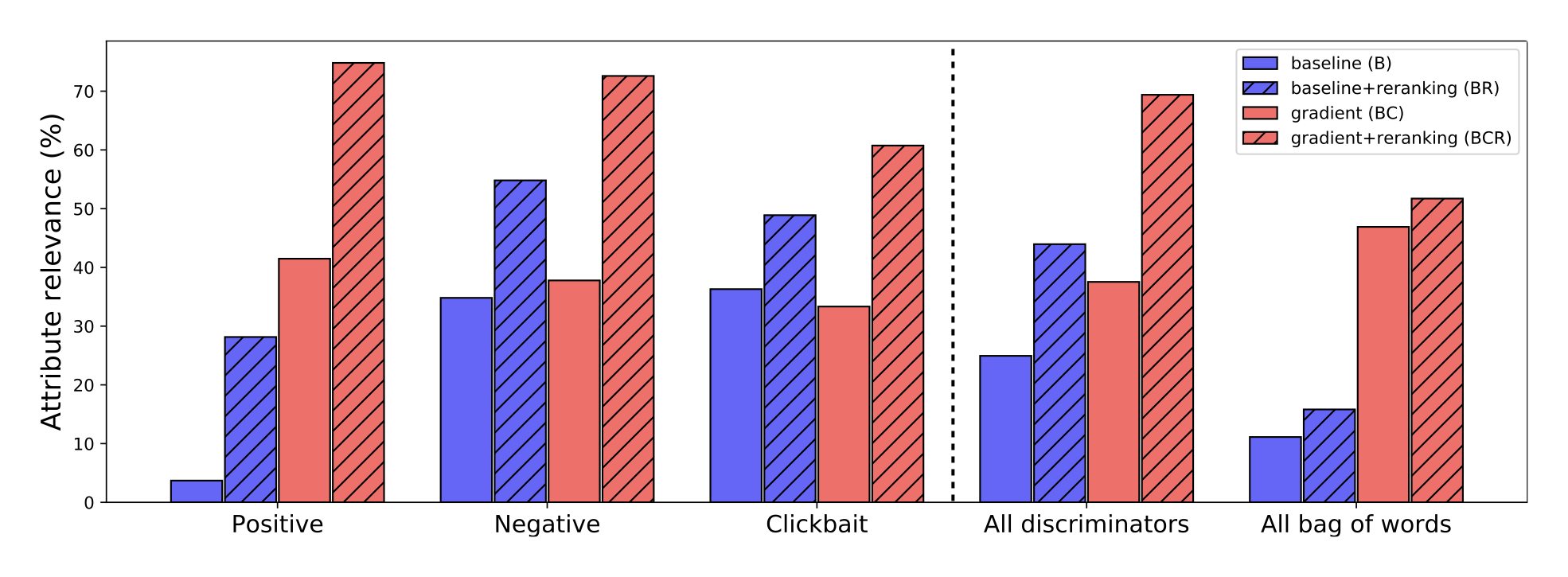
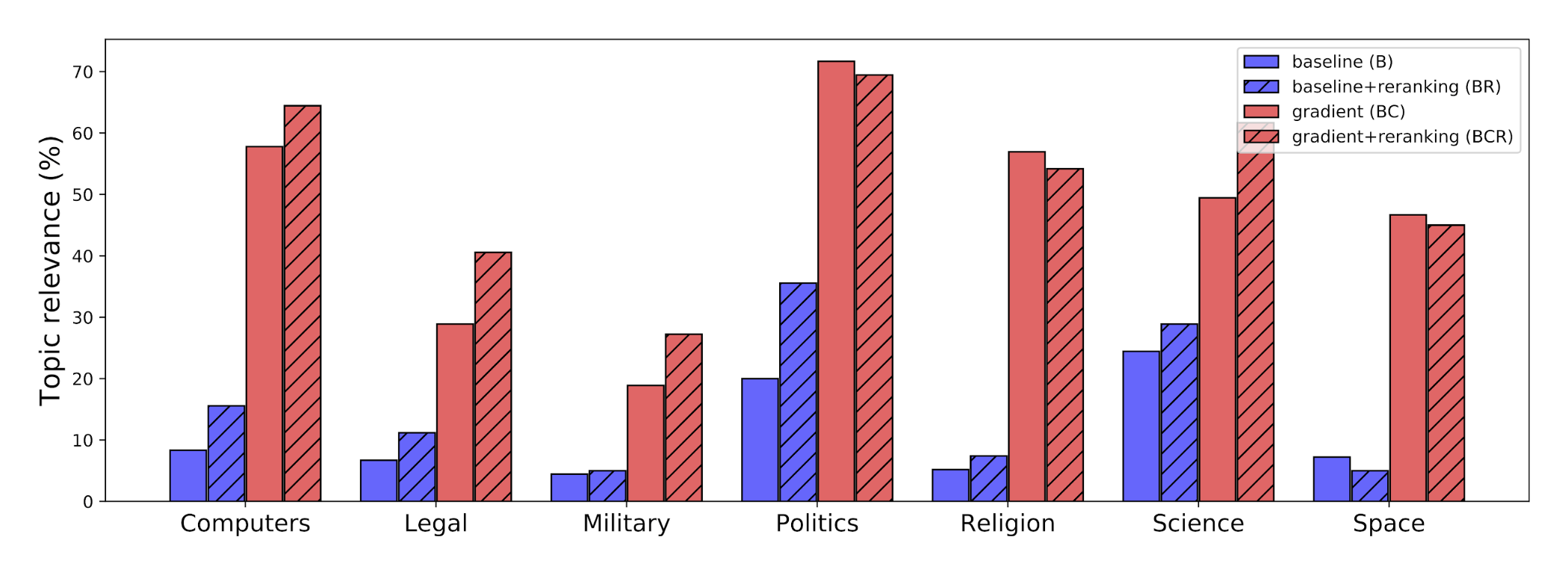
Plug and Play Language Models (PPLMs) are a way to steer large language models like GPT-2 with attribute models 100,000 times smaller, making meaningful progress toward controllable language generation.
Other approaches fine-tune the original language model, but that is expensive given the number of parameters involved, and must be done separately for each attribute. Moreover, fine-tuning requires attribute-specific training data, which can be hard to obtain.
A better approach is conditional language generation, where a control code is presented to the model and the model generates text conditioned on it. CTRL is an example. Still, one needs to train a huge model from scratch, which is slow and expensive.
In PPLM, we do not retrain the original language model (the mammoth in the pictures). Instead, we plug in a small auxiliary model (the mouse) that steers the large model at each generation step by modifying its latent representations to increase the probability of the desired attribute. The attribute models can be either bags of words representing a topic, or small models trained on a labeled dataset. In our experiments we tested both topical bags of words covering science, military, and politics, and attribute models for sentiment, toxicity, and clickbaitiness.
A paper describing PPLMs was accepted at ICLR 2020 (here is the 5-minute video poster), and we also wrote a blogpost about it in a very readable format with minimal math.
We released the code in two ways: as a fixed version for reproducibility on the Uber Research repository together with an example Colab notebook, and as a contribution to the Hugging Face Transformers repository. Our friends at Hugging Face also built an interactive demo.
The work received wide press coverage: VentureBeat, MIT Technology Review, InfoQ, and coverage in Chinese. The blog post reached the front page of Hacker News twice and r/MachineLearning, and Kyunghyun Cho discussed the work in his NeurIPS 2019 tutorial.