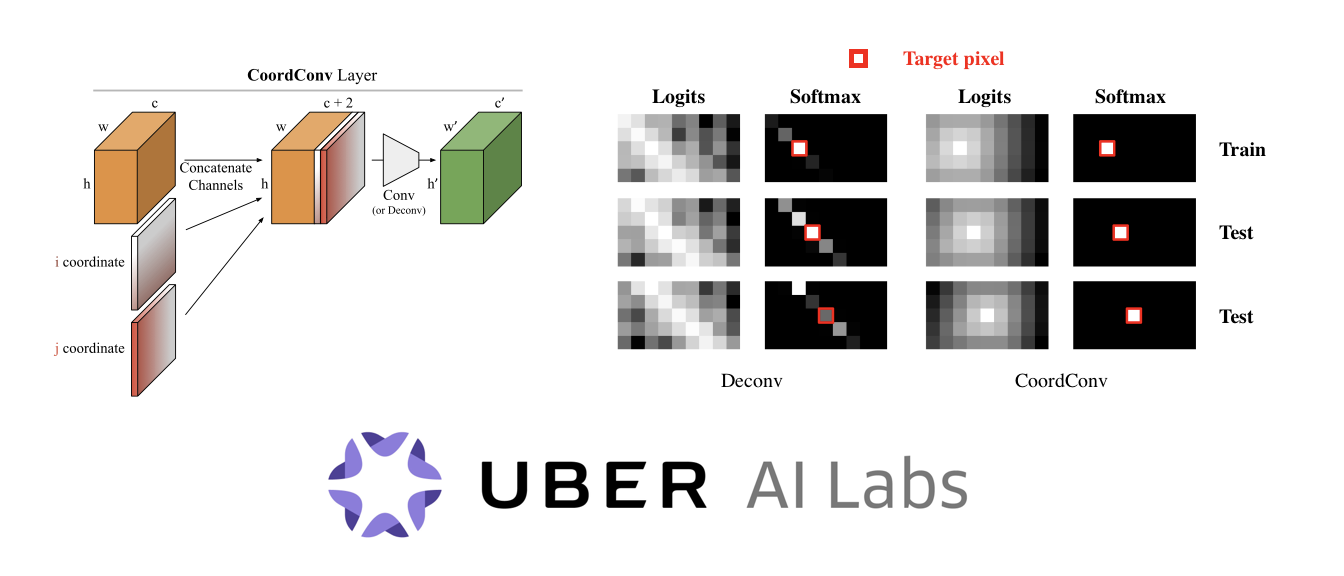

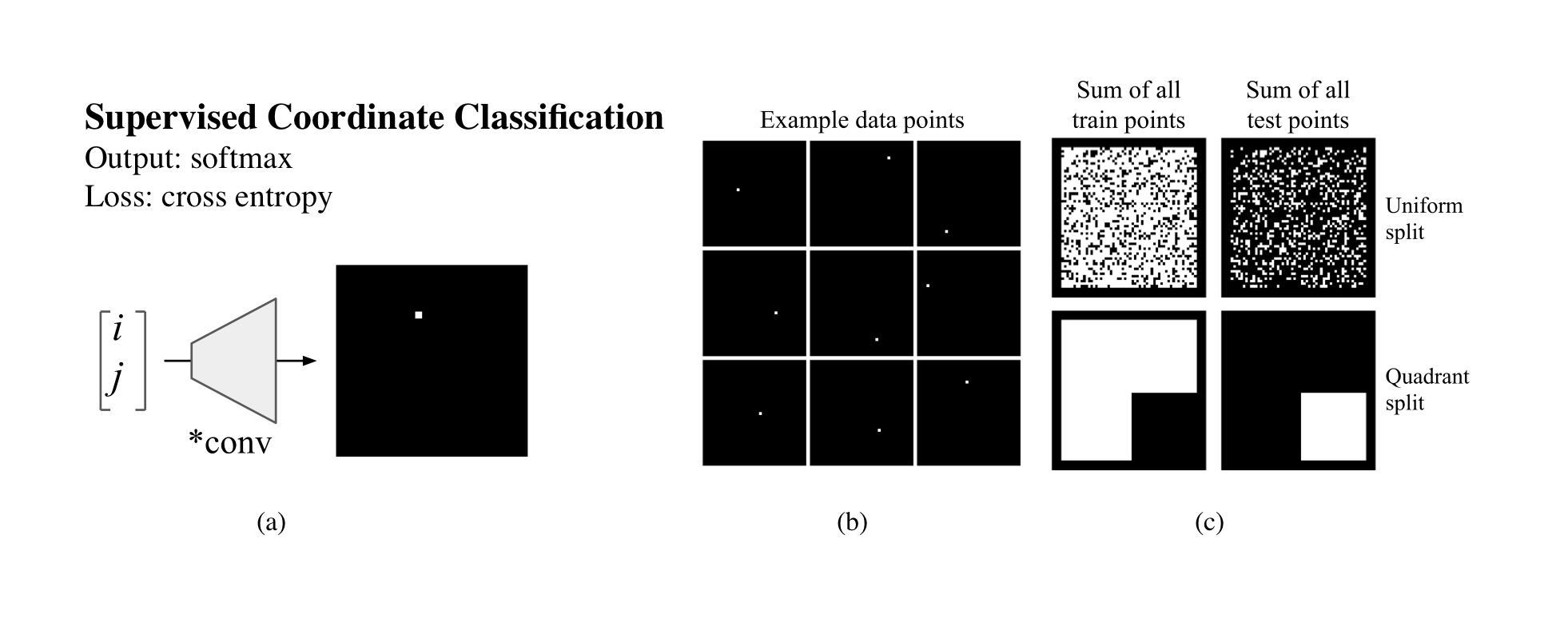
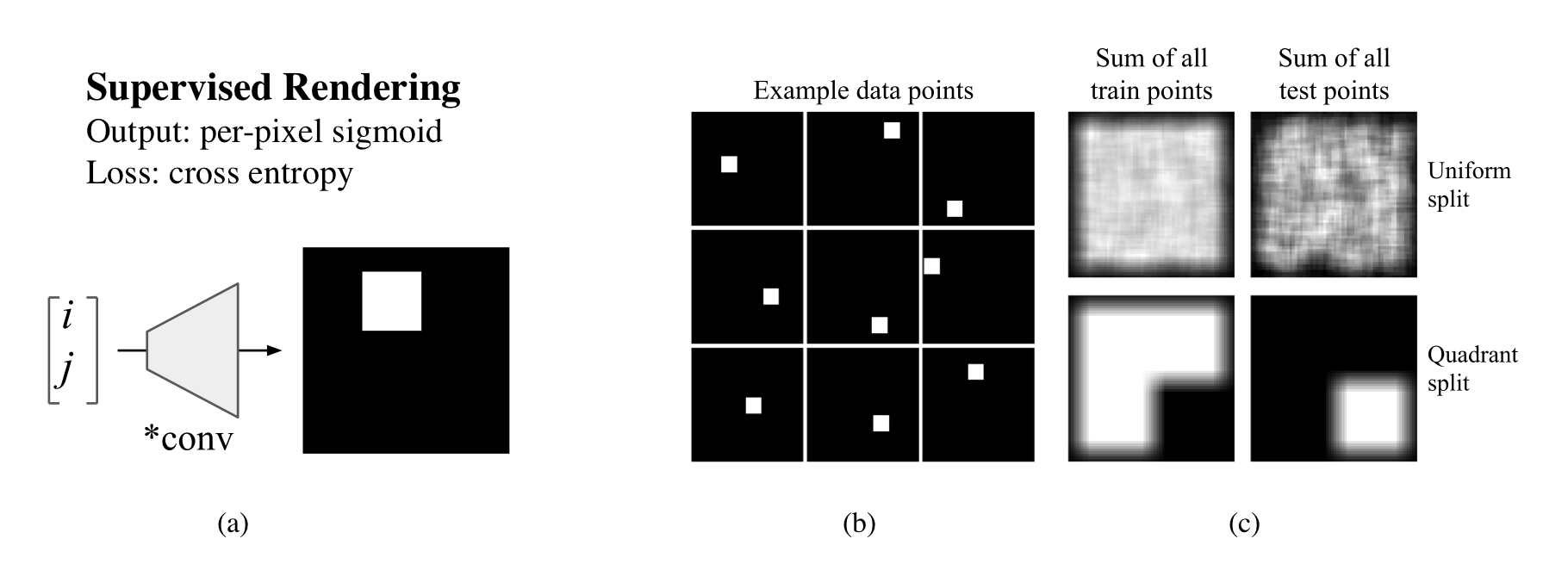
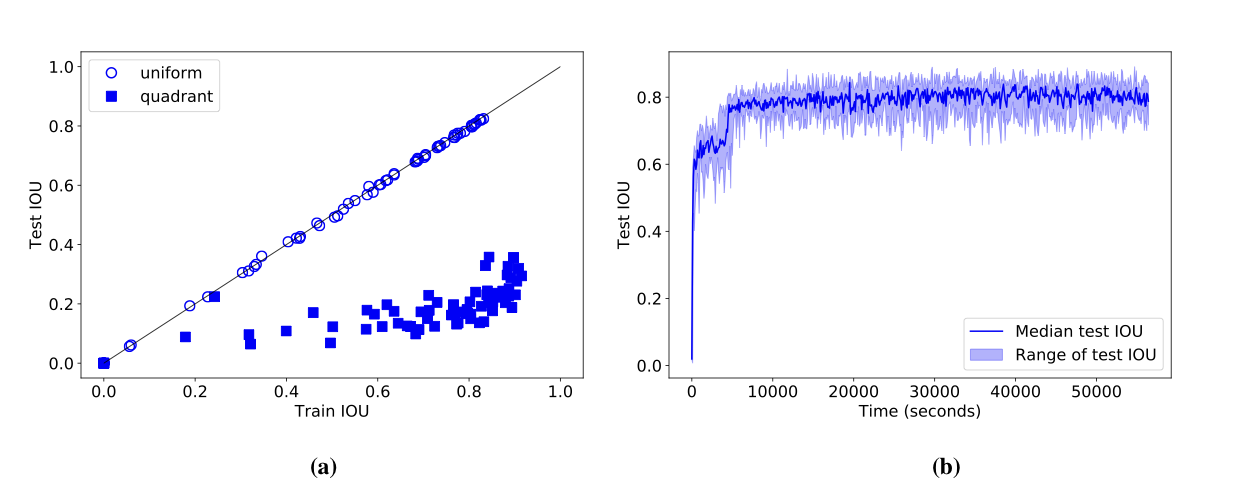

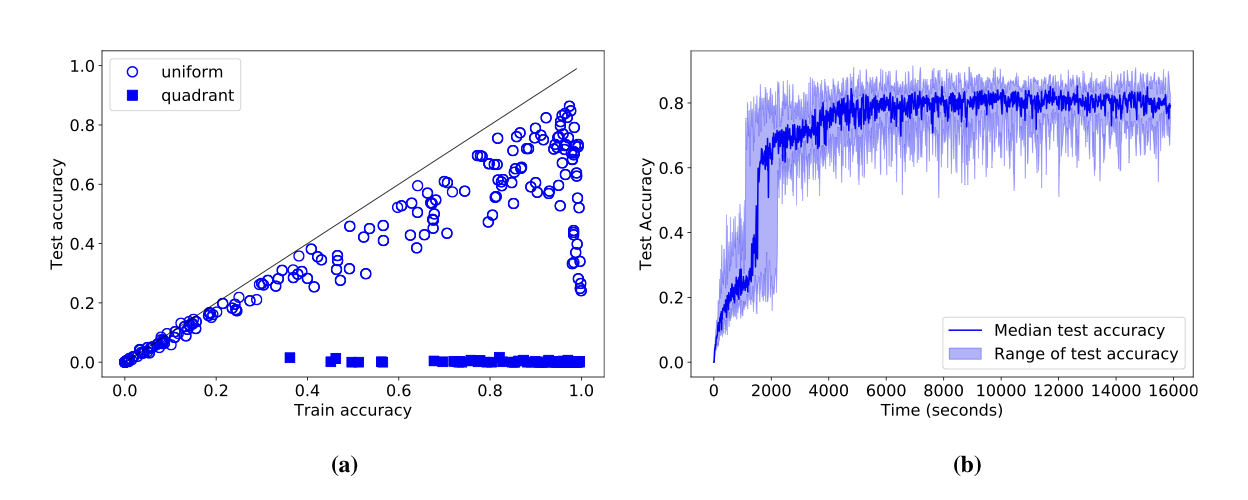
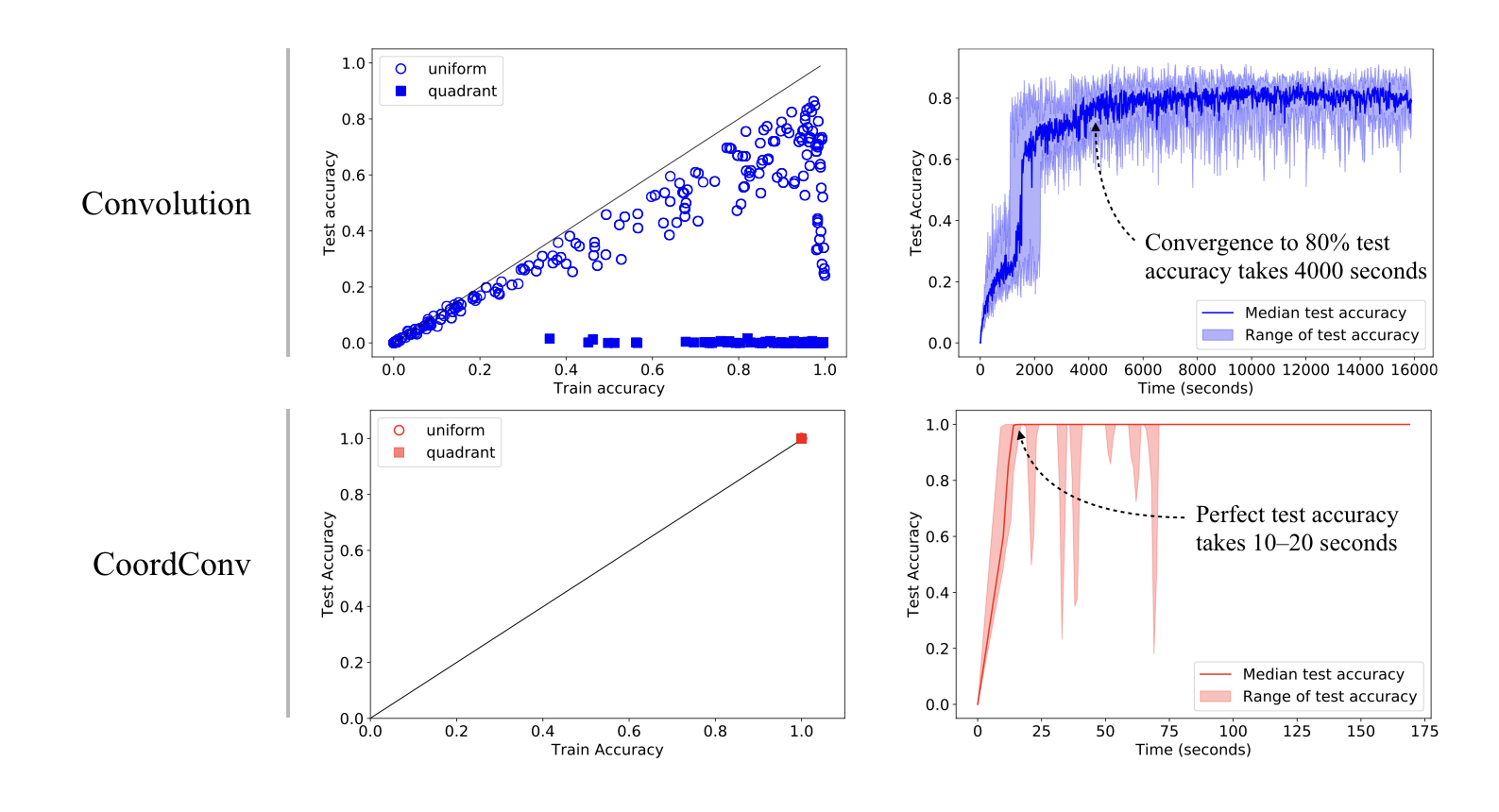
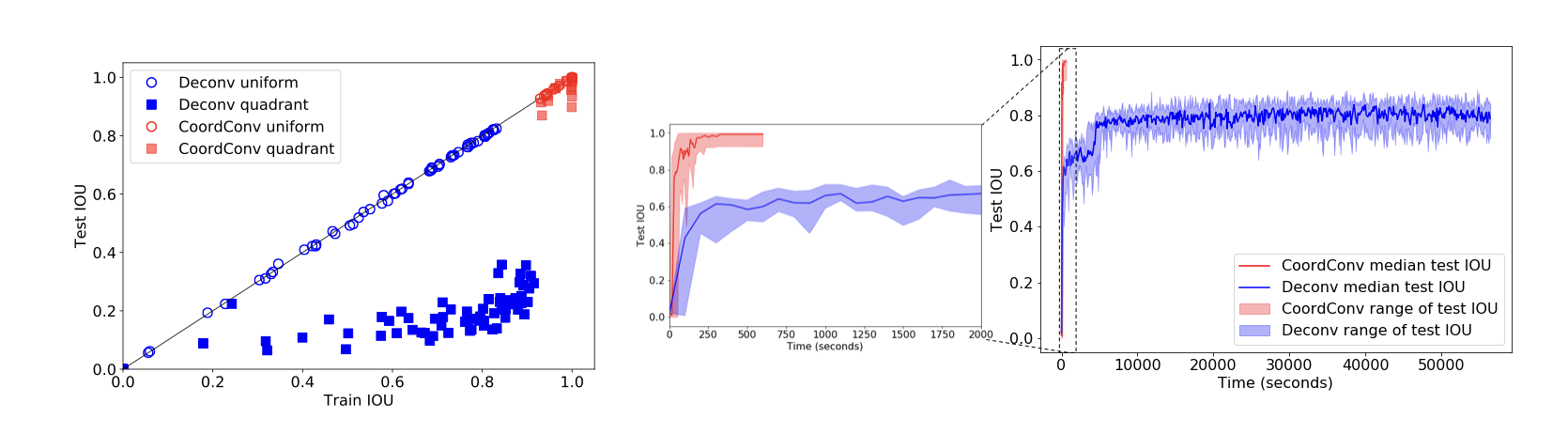
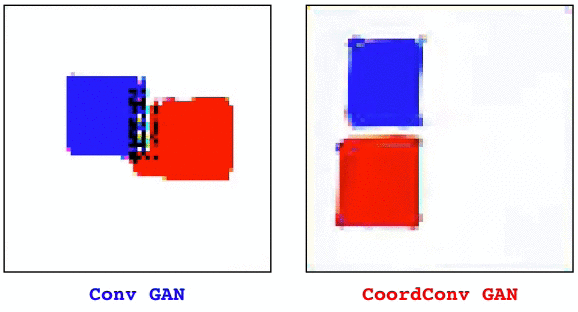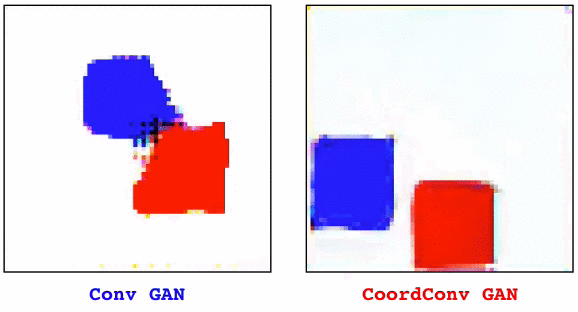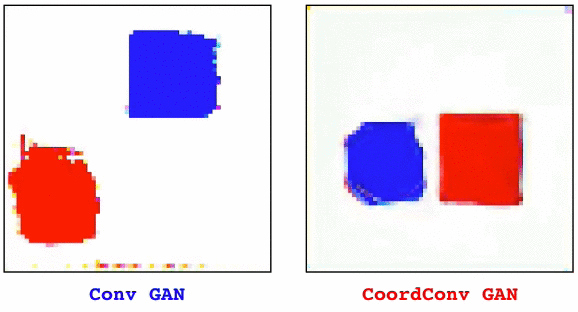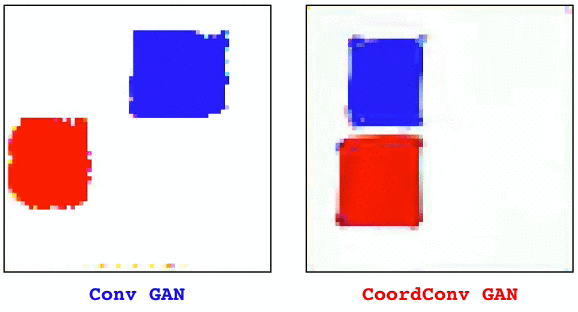
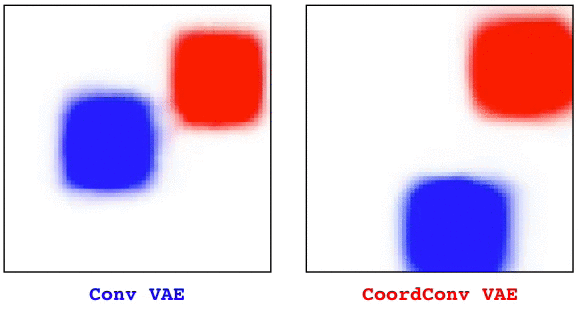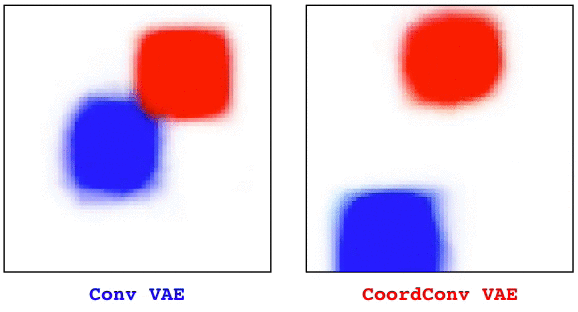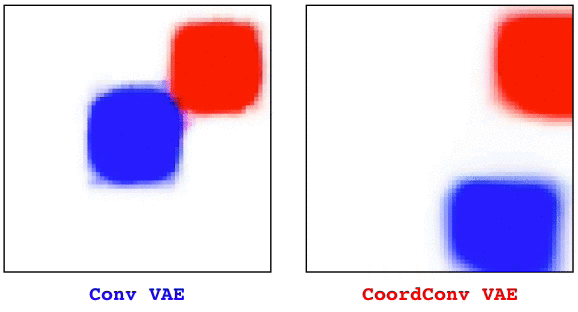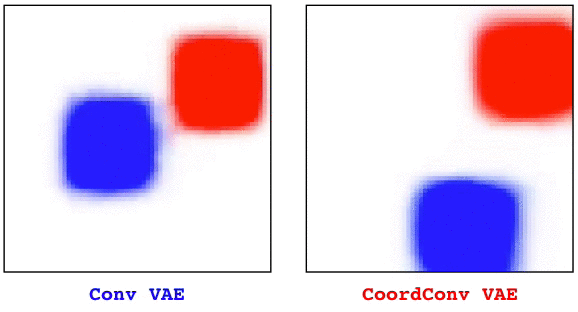


Convolutional layers are translation equivariant. This is a nice property, but in scenarios where the position of objects is important, convolutional layers fail at the task.
In this research we first identified a set of toy tasks where convolution fails, then we proposed a simple solution and we show how not only it solves those tasks perfectly, but is also useful for solving all sort of other more realistic tasks, from image autoencoders, to GANs, from object detection to Atari playing agents trained with reinforcement learning.
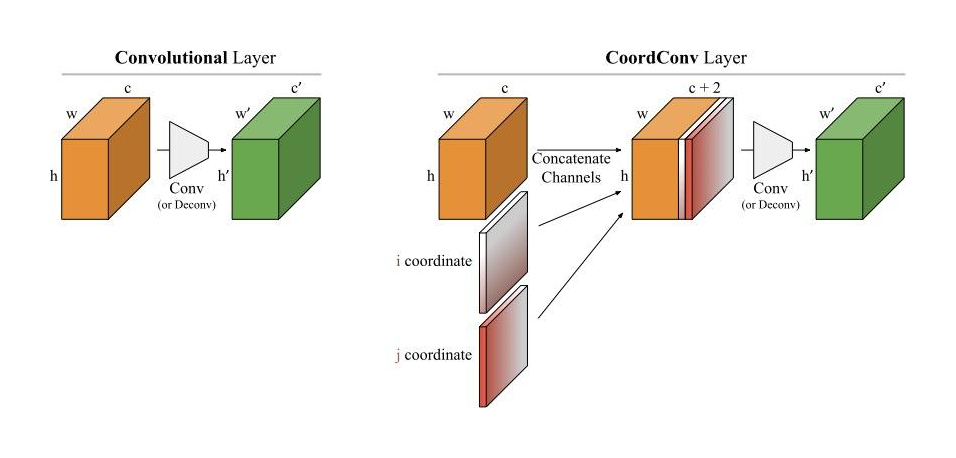
The solution, that we call CoordConv and is a drop-in replacement for a convolutional layer, consist in simply concatenating the coordinate information to the input before performing the convolution, creating two additional channels for x and y. This really simple approach works surprisingly well.
The paper presenting this work was accepted at NIPS 2018, and we wrote a blogpost about it.
Rosanne, Joel and Jason put together a very funny video explaining the main idea in the paper.
Rosanne gave a public presentation about it that was recorded.
Also a lot of commentary followed, with Yann LeCun (Turing award winner) called it a “super simple idea from Uber” that “improves generalization performance [and] the quality of GAN-generated images”. There has been also a pretty active thread on Reddit.
After we released our code, there have been many implementations for different deep learning frameworks appeared on GitHub.